Основы объектно-ориентированного программирования
Факторизация Общего Поведения
Если требование Независимости Представлений отражает позицию клиента - игнорирование внутренних деталей и вариантов реализации - то последнее требование отражает позицию разработчиков повторно используемых классов. Их цель в получении преимуществ от любой общности (commonality), которая может существовать в семействе или подсемействе реализаций.
Многообразие реализаций, имеющее место в некоторых проблемных областях, требует, как уже отмечалось, решения, основанного на семействе модулей. Часто это семейство настолько велико, что естественно поискать соответствующие подсемейства. В случае табличного поиска первая попытка классификации может привести к трем обширным подсемействам:
- Таблицы, организуемые по некоторой схеме хеширования.
- Таблицы, организуемые как некоторая разновидность деревьев.
- Таблицы, организуемые последовательно.
Каждая из этих категорий охватывает много вариантов, но в большинстве случаев можно найти существенную общность между этими вариантами. Рассмотрим, например, семейство последовательных реализаций - таких, в которых элементы сохраняются и отыскиваются в порядке их первоначального включения в таблицу.
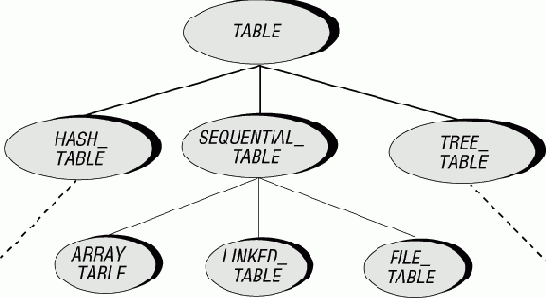
Рис. 4.1. Некоторые возможные реализации таблицы
Возможными представлениями последовательной таблицы являются массив, связный список и файл. Но независимо от варианта такой реализации, клиенты должны иметь возможность для любой последовательно организованной таблицы рассматривать ее элементы один за другим, перемещая (воображаемый) курсор, указывающий позицию элемента, рассматриваемого в настоящий момент. При таком подходе можно переписать подпрограмму поиска для последовательных таблиц в виде:
has (t: SEQUENTIAL_TABLE; x: ELEMENT): BOOLEAN is -- Содержится ли x в последовательной таблице t? do from start until after or else found (x) loop forth end Result := not after end
Это представление основано на использовании четырех подпрограмм, которые должны иметься в любой последовательной реализации таблицы(Подробно методика работы с курсором будет рассмотрена в лекции 5 курса "Основы объектно-ориентированного проектирования""Активные структуры данных" ("Active data structures"). ):
- start (начать) , переместить курсор к первому элементу, если он имеется.
- forth (следующий) , переместить курсор к следующей позиции.
- after (после) , булев запрос, переместился ли курсор за последний элемент.
- found (x) , булев запрос, возвращающий true, когда курсор указывает на элемент, имеющий значение x.
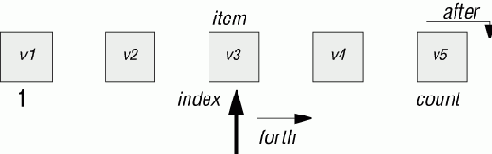
Рис. 4.2. Последовательная структура с курсором
Несмотря на сходство с шаблоном подпрограммы, использованным в начале этого обсуждения, новый текст - это уже не шаблон, это настоящая подпрограмма, написанная в непосредственно исполняемой нотации (такая нотация используется в лекциях 7-18 этого курса). Если задать реализации для четырех операций start, forth, after и found, то можно откомпилировать и выполнить последнюю версию has.
Каждое представление последовательной таблицы требует соответствующего представления курсора. Три примера таких представлений основаны на работе с массивом, связным списком и файлом.
В первом из них используется массив из capacity элементов, и таблица занимает позиции от 1 до count + 1. (Последнее значение необходимо в случае, когда курсор переместился на позицию после ("after") последнего элемента.)

Рис. 4.3. Представление последовательной таблицы с курсором на основе массива
Во втором представлении используется связный список, в котором доступ к первому элементу обеспечивается по ссылке first_cell и каждый элемент связан со следующим по ссылке right. При этом курсор можно представить ссылкой cursor.

Рис. 4.4. Представление последовательной таблицы с курсором на основе связного списка
В третьем представлении используется последовательный файл, в котором курсор представляет просто текущую позицию чтения.
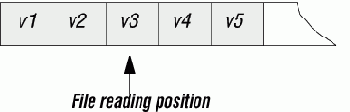
Рис. 4.5. Представление последовательной таблицы с курсором на основе последовательного файла
Реализация операций start, forth, after и found будет разной для каждого из вариантов.
В следующей таблице3)
показана реализация для каждого случая. Здесь t @ i означает i-й элемент массива t, который записывается как t [i] в языках Pascal или C; Void означает "пустую" ссылку; обозначение f- языка Pascal, для файла f, означает элемент в текущей позиции чтения из файла.
| Массив | i :=1 | i :=i + 1 | i >count | t @ i =x |
| Связный список | c := first_cell | c :=c. right | c =Void | c. item =x |
| Файл | rewind | read | end_of_file | f -=x |
Все варианты последовательной таблицы совместно используют функцию has, и отличаются только реализацией операций. Хорошее решение проблемы повторного использования требует, чтобы в такой ситуации текст has находился бы лишь в одном месте, связанном с общим понятием последовательной таблицы. Для описания каждого нового варианта не нужно больше беспокоиться о подпрограмме has; требуется лишь подготовить подходящие версии start, forth, after и found.